Model Pipeline
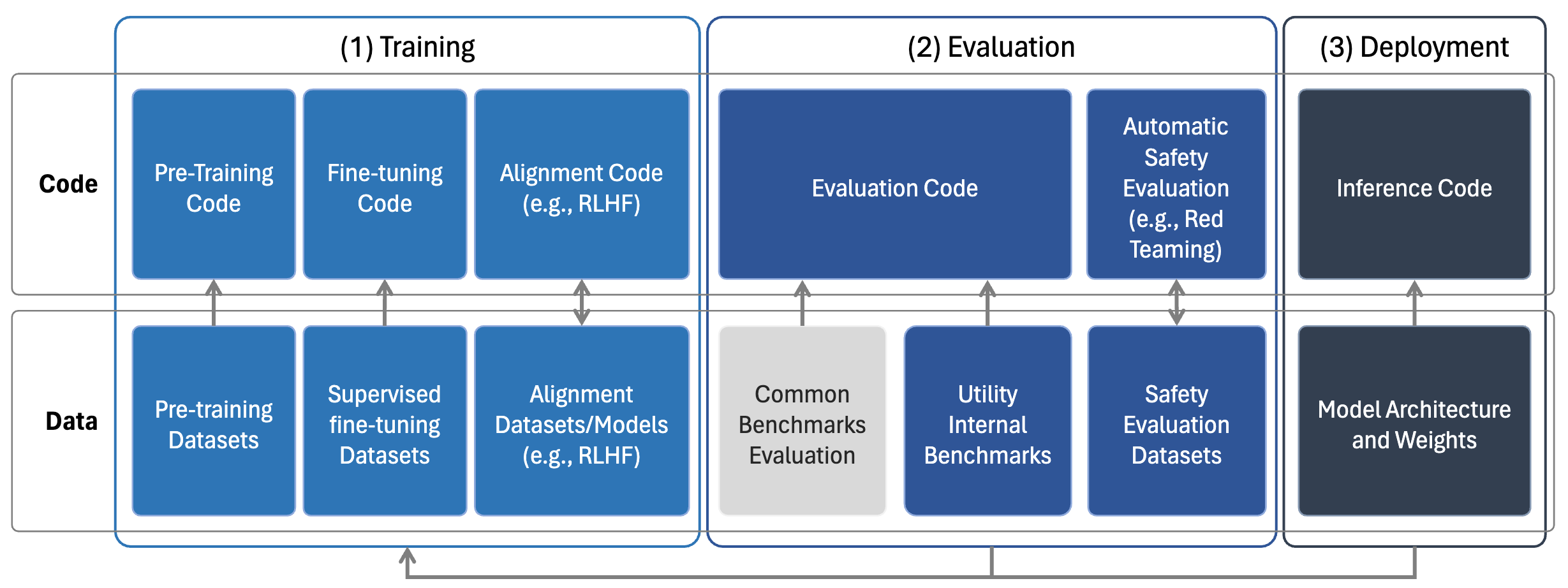
Figure 1. Pipeline of the components of model (1) training, (2) evaluation and (3) deployment for typical LLMs.
There are several components involved in the (1) training, (2) evaluation and (3) deployment pipeline to obtain a Large Language Model (LLM). Model developers decide whether to make each component of those pipelines
private
or public
, with varying levels of restrictions for
the latter. These are summarized in Figure 1, and detailed below.
Model training processes can be grouped into three distinct stages:
pre-training
, where a model is exposed to large-scale
datasets composed of trillions of tokens of data, with the
goal of developing fundamental skills and broad knowledge;
supervised fine-tuning (SFT)
, which corrects for data quality issues in pre-training datasets using a smaller amount
of high-quality data; and alignment
, focusing on creating
application-specific versions of the model by considering
human preferences. Once trained, models are usually evaluated on openly available evaluation datasets (e.g., MMLU
by Hendrycks et al., 2020) as well as curated benchmarks
(e.g., HELM by Liang et al., 2022). Some models are also
evaluated on utility-oriented proprietary datasets held internally by developers, potentially by holding out some of
the SFT/alignment data from the training process (Touvron
et al., 2023a). On top of utility-based benchmarking, developers sometimes create safety evaluation mechanisms
to proactively stress-test the outputs of the model (e.g., red
teaming via adversarial prompts). Finally, at the deployment
stage, content can be generated by running the inference
code with the associated model weights.
Classifying Openness
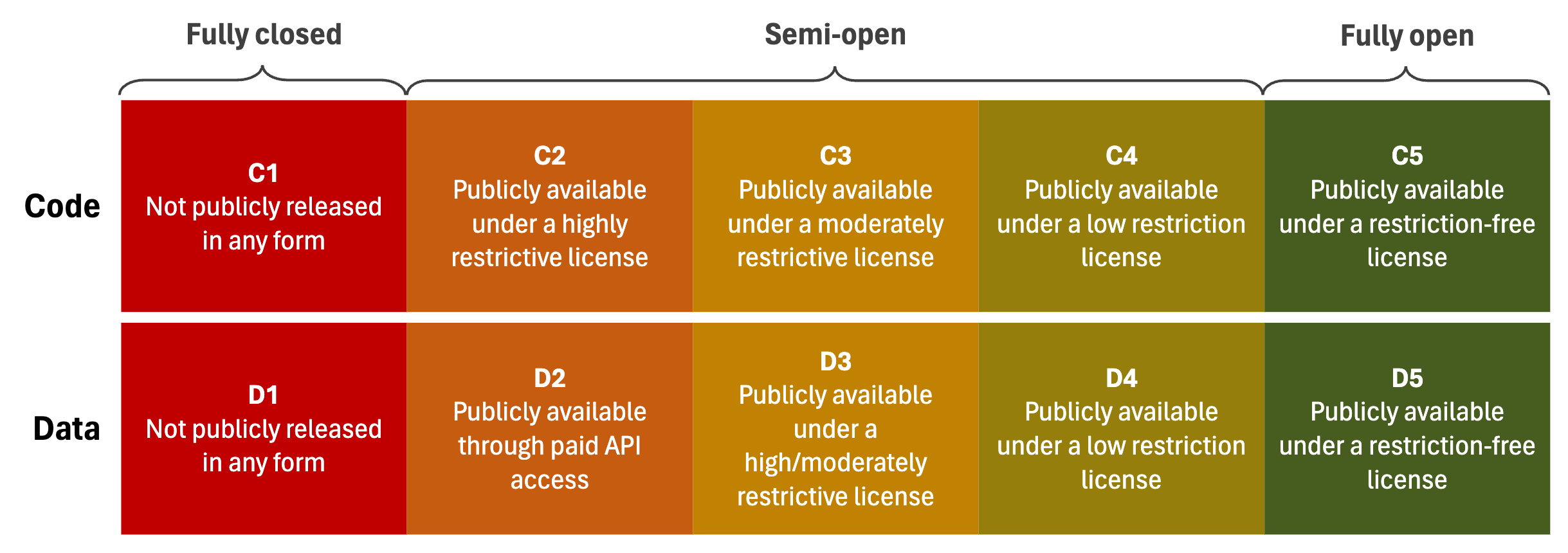
Figure 2. Categorization of the levels of openness of the code and data of each model component.
To categorize the openness of each component, we introduce the scale presented in Figure 2. At the highest level, a
fully closed
component is not publicly
accessible in any form. In contrast, a
semi-open
component is publicly accessible but with certain
limitations on access or use, or it is available in a restricted
manner, such as through an Application Programming Interface (API). Finally, a fully open
component is available to the public without any restrictions
on its use.
Further, the semi-open category comprises three subcategories, delineating varied openness levels (see Figure 2). Distinctions are made between Code (C1-C5) and Data (D1-D5) components, where C5/D5 represents unrestricted availability and C1/D1 denotes complete unavailability. For semi-open components, their classification relies on the license of the publicly available code/data.
To evaluate the licenses we introduce a point-based system where each license gets 1 point (for a total maximum of 5) for allowing each of the following:
- can use a component for research purposes (Research)
- can use a component for any commercial purposes (Commercial Purposes)
- can modify a component as desired (with notice) (Modify as Desired)
- can copyright derivative (Copyright Derivative Work)
- publicly shared derivative work can use another license (Other license derivative work)
The total number of points is indicative of a license's restrictiveness. A
Highly restrictive
license scores 0-1 points, aligning with
openness levels of code C2 and data D3, imposing significant limitations. A Moderately restrictive
license, scoring
2-3 points (code C3 and data D3), allows more flexibility
but with some limitations. Licenses scoring 4 points are
Slightly restrictive
(code C4 and data D4), offering broader
usage rights with minimal restrictions. Finally, a Restriction free
license scores 5 points, indicating the highest level
of openness (code C5 and data D5), permitting all forms of
use, modification, and distribution without constraints.